CVPR 2025
Oral
MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds
Abstract
Recent sparse multi-view scene reconstruction advances like DUSt3R and MASt3R no longer require camera calibration and camera pose estimation. However, they only process a pair of views at a time to infer pixel-aligned pointmaps. When dealing with more than two views, a combinatorial number of error prone pairwise reconstructions are usually followed by an expensive global optimization, which often fails to rectify the pairwise reconstruction errors. To handle more views, reduce errors, and improve inference time, we propose the fast single-stage feed-forward network MV-DUSt3R. At its core are multi-view decoder blocks which exchange information across any number of views while considering one reference view. To make our method robust to reference view selection, we further propose MV-DUSt3R+, which employs cross-reference-view blocks to fuse information across different reference view choices. To further enable novel view synthesis, we extend both by adding and jointly training Gaussian splatting heads. Experiments on multi-view stereo reconstruction, multi-view pose estimation, and novel view synthesis confirm that our methods improve significantly upon prior art. Code will be released.
Overview
The proposed Multi-View Dense Unconstrained Stereo 3D Reconstruction Prime (MV-DUSt3R+) is able to reconstructs large scenes from multiple pose-free RGB views. Top row: one single-room scene and one large multi-room scene reconstructed by MV-DUSt3R+ in 0.89 and 1.54 seconds using 12 and 20 input views respectively (only a subset is shown for visualization). Bottom row: MV-DUSt3R+ is able to synthesize novel views by predicting pixel-aligned Gaussian parameters. Reconstruction of such large scenes are challenging for prior methods (e.g. DUSt3R)
MV-DUSt3R
Visual tokens for the reference view and other source views are shown in Blue and Green. Black straight solid lines indicate the primary token flow while gray lines indicate secondary token flow.
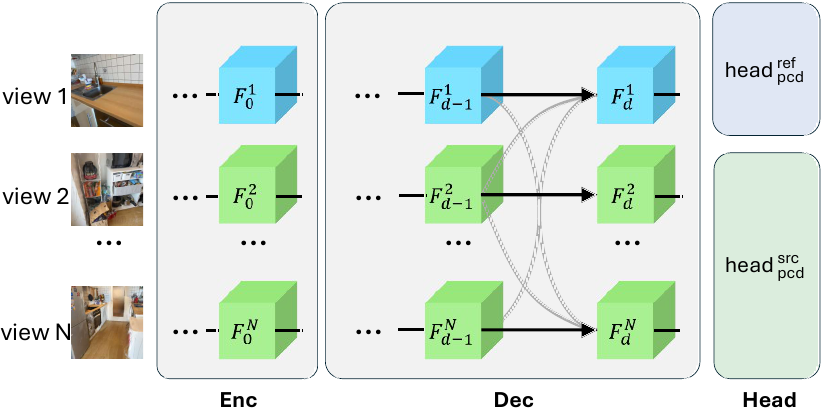
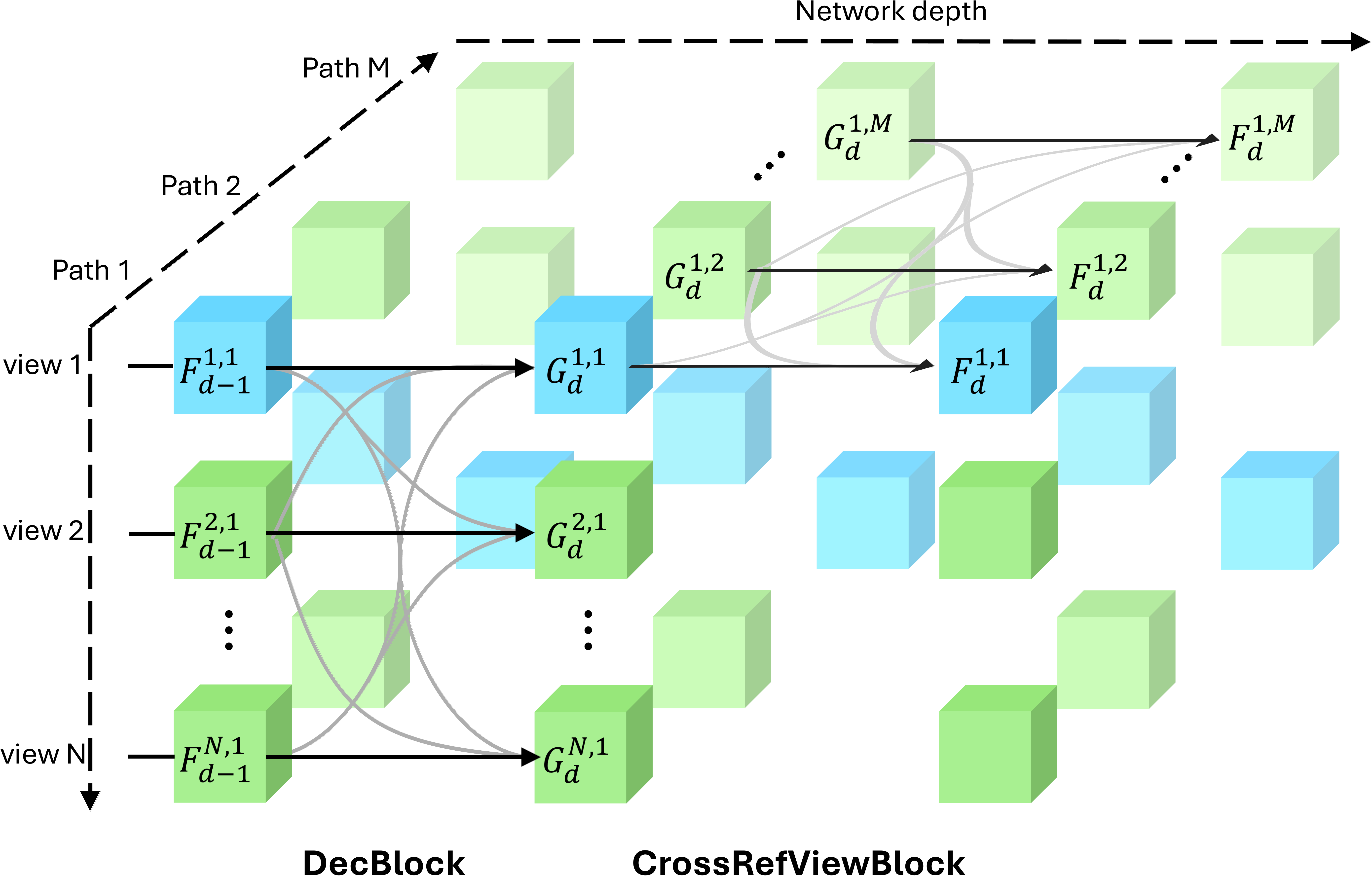
MV-DUSt3R+
DecBlock and CrossRefViewBlock in MV-DUSt3R+: tokens of the reference and other views are highlighted in blue and green, respectively. Each model path uses a different reference view. For clarity, only 1 of stacked DecBlock and CrossRefViewBlock are shown.
Qualitative Results (8~20 views)
MVS reconstruction and NVS qualitative results. We show one method in each column, which includes the reconstructed pointcloud and 1 rendered new view. Incorrectly reconstructed geometry is highlighted in red boxes. DUSt3R often introduces incorrect pairwise reconstructions when the scene has multiple objects with similar appearance (e.g., windows, chairs, doors), which can not be recovered by the global optimization. MV-DUSt3R is more robust overall but still sometimes fails to reconstruct geometry accurately in regions far away from the reference view, while MV-DUSt3R+ predicts geometry more evenly across the space.

Qualitative Results (100 views)
MVS reconstruction results with 100-view inputs on ScanNet and HM3D. 3% of the predicted points with low confidence score are filtered out (the same below). Qualitatively we find the reconstructed scene geometry to be very similar to the groundtruth. This shows that our MV-DUSt3R+ model, trained with 8-view samples, can generalize remarkably well to 100-view inputs for single-room scenes. The inference time for 100 views is 19.1 seconds.

